Unlabeled Data In Machine Learning
Category: MACHINELEARNING | 4th July 2025, Friday
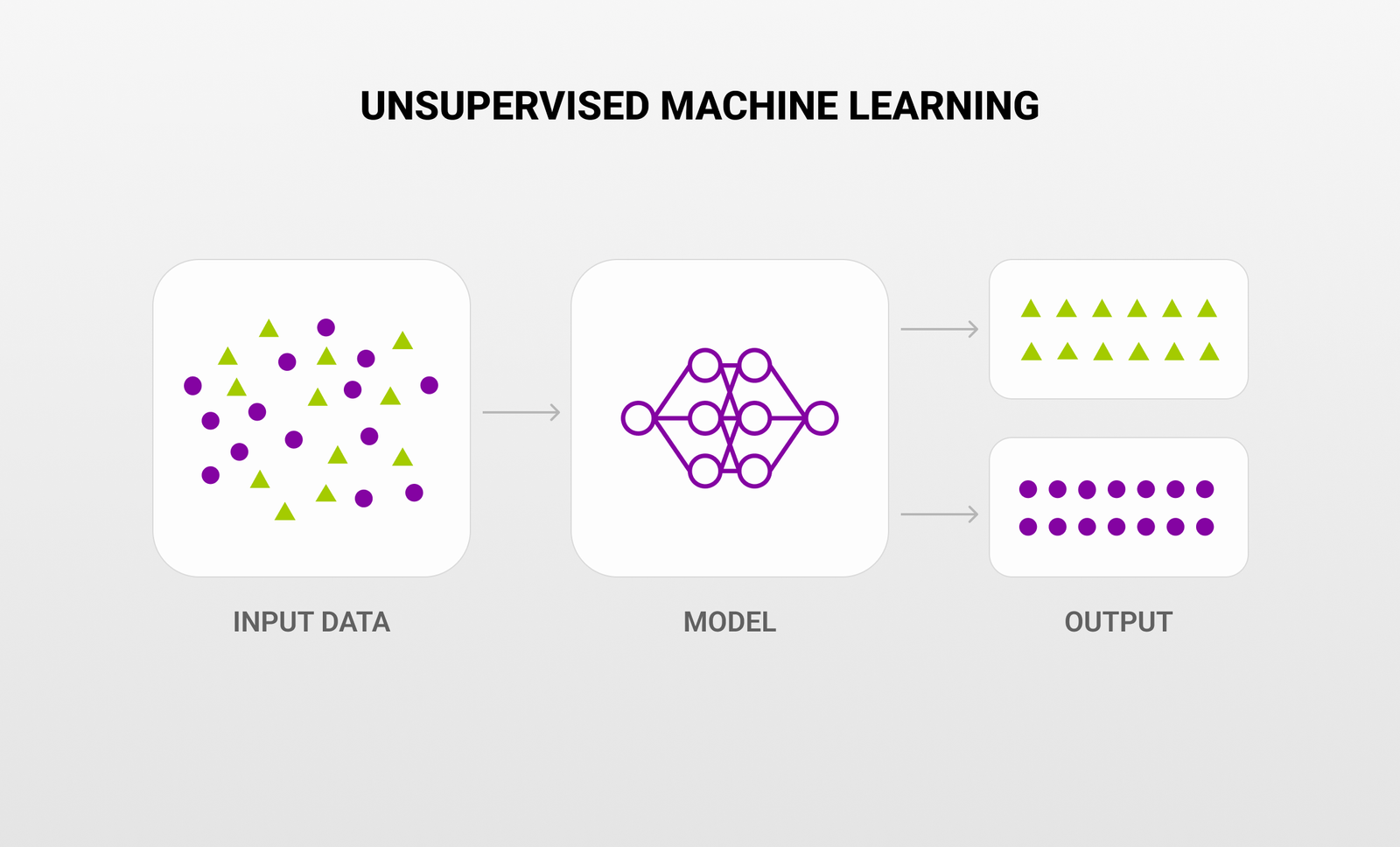
Introduction
Data Is The Cornerstone Of Machine Learning Systems. While Much Attention Is Given To labeled Data In Supervised Learning, A Vast Majority Of Real-world Data Is unlabeled. From Large Image Collections To Text Corpora, Most Datasets Lack Human-assigned Labels. Understanding unlabeled Data Is Critical For Advanced Machine Learning, Particularly In Fields Such As unsupervised Learning, Semi-supervised Learning, And Self-supervised Learning.
What Is Unlabeled Data?
Unlabeled Data Refers To Data Points That Have input Features But do Not Contain Any Corresponding Output Or Target Labels. In Simpler Terms, We Only Know The observations (input Variables), But We Lack Any Predefined Classification, Category, Or Expected Result.
Unlike Labeled Data (which Provides Correct Answers), Unlabeled Data Requires Models To Automatically Learn Inherent Patterns, Structures, Or Groupings Without Explicit Supervision.
Examples:
| Input Data Type | Example (Unlabeled) |
|---|---|
| Images | A Folder Of Photos Without Category Tags |
| Text | Tweets Without Sentiment Annotations |
| Transactions | Online Shopping Data Without Fraud Labels |
| Sensor Data | IoT Sensor Readings Without Fault Indications |
Mathematical Perspective:
Given A Dataset D={x1,x2,...,xn}D = \{x_1, X_2, ..., X_n\} Where Each xi∈Rdx_i \in \mathbb{R}^d Represents A Feature Vector Of Dimension dd, unlabeled Data Refers To Datasets Where No Corresponding Target Variable yiy_i Is Provided.
In Contrast, labeled Data Would Have Pairs (xi,yi)(x_i, Y_i).
Why Unlabeled Data Matters?
-
Abundance In The Real World:
Nearly 90%+ Of Data Generated Is Unlabeled, Such As Text, Audio, And Video. -
Labeling Cost:
Annotating Data (e.g., Labeling Medical Images Or Translating Documents) Can Be Time-consuming And Expensive. -
Exploratory Learning:
Unlabeled Data Allows For Discovering Hidden Structures, Relationships, And Latent Features.
Applications Of Unlabeled Data:
| Field | Use Of Unlabeled Data |
| Computer Vision | Clustering Images Into Categories (e.g., Faces, Objects) |
| Natural Language Processing | Topic Modeling On Large Document Corpora Without Labeled Sentiment |
| Cybersecurity | Detecting Unusual Network Behaviors (anomalies) |
| Biology | Clustering Gene Expression Data |
| Recommender Systems | Learning User-item Interaction Patterns From Implicit Feedback |
Techniques For Learning From Unlabeled Data
1. Unsupervised Learning
-
Algorithms Explore The Structure Of The Data Without Labels.
-
Key Goals: Clustering, Density Estimation, Dimensionality Reduction.
-
Common Algorithms:
-
K-Means Clustering: Groups Similar Data Points Into Clusters.
-
Hierarchical Clustering: Builds Tree-like Structures Of Data Groups.
-
Principal Component Analysis (PCA): Reduces Dimensionality By Projecting Data To Principal Components.
-
Autoencoders: Neural Networks That Learn Efficient Data Encodings.
-
2. Semi-Supervised Learning
-
Combines A Small Amount Of Labeled Data With A Large Amount Of Unlabeled Data.
-
Uses Unlabeled Data To Improve Learning Accuracy.
-
Algorithms:
-
Self-training
-
Graph-based Methods
-
Pseudo-labeling
-
3. Self-Supervised Learning (Advanced Topic)
-
Generates pseudo-labels From Unlabeled Data Through Pretext Tasks.
-
Widely Used In Large-scale Natural Language Processing (e.g., BERT) And Computer Vision Models.
Challenges Of Using Unlabeled Data
1. Interpretability
-
The Meaning Of Learned Clusters Or Representations Might Not Always Be Clear Or Interpretable.
2. Ambiguity In Evaluation
-
No Ground Truth Labels Make It Difficult To Quantify Model Performance Directly.
3. High-Dimensionality Issues
-
Unlabeled Data In High Dimensions Can Suffer From The "curse Of Dimensionality," Where Meaningful Structure Becomes Difficult To Detect.
4. Algorithmic Sensitivity
-
Many Unsupervised Algorithms Are Sensitive To Hyperparameters Like The Number Of Clusters In K-Means (kk).
Real-World Example: K-Means Clustering On Unlabeled Data
Suppose We Have An Unlabeled Dataset Of Handwritten Digits.
Step 1: Input
A Set Of Images, Each Represented As A Feature Vector (e.g., Pixel Intensities), With No Digit Labels.
Step 2: Apply K-Means
Run K-Means Clustering With k=10k = 10 (assuming We Want 10 Clusters, One For Each Digit).
Step 3: Output
The Algorithm Assigns Each Image To One Of 10 Clusters, Grouping Similar Digits Together.
No Label Was Provided, Yet Digits With Similar Shapes Cluster Together Due To The Inherent Structure In The Data.
Key Insight For IIT Students:
In Research And Industry, Leveraging Unlabeled Data Efficiently Is Crucial:
-
Modern AI Systems Like ChatGPT (Large Language Models) Initially Train On Unlabeled Text.
-
Advances In representation Learning And contrastive Learning Often Start With Purely Unlabeled Data.
-
Emerging Fields Like foundation Models Depend On Huge Unlabeled Datasets (text, Image, Code, Etc.).
Summary Table:
| Aspect | Unlabeled Data |
|---|---|
| Contains Labels? | No |
| Common Learning Type | Unsupervised Learning, Self-Supervised Learning |
| Typical Tasks | Clustering, Dimensionality Reduction, Representation Learning |
| Algorithms | K-Means, PCA, DBSCAN, Autoencoders |
| Real-World Relevance | Very High (Majority Of Available Data) |
Conclusion
Unlabeled Data Represents The Vast Majority Of Available Data In The World And Plays A Fundamental Role In Advancing Machine Learning Techniques, Particularly Unsupervised, Semi-supervised, And Self-supervised Learning.
For IIT Students Pursuing data Science, Artificial Intelligence, Or Advanced Computing, It Is Essential To:
-
Understand How To Process And Analyze Unlabeled Datasets.
-
Explore Dimensionality Reduction And Clustering Methods.
-
Learn How To Leverage Unlabeled Data For Model Pretraining And Feature Extraction.
Mastery Of Unlabeled Data Techniques Equips Students For Real-world Problems Where Labeled Data Is Scarce, Expensive, Or Unavailable.
Tags:
Unlabeled Data In Machine Learning, What Is Unlabeled Data
