Pipelining And Parallel Processing – Concepts, Architecture, And Applications
Category: COMPUTER SCIENCE | 1st November 2025, Saturday
Modern Computer Systems Aim To Achieve High Performance, Faster Computation, And Efficient Use Of Hardware Resources. Two Of The Most Crucial Techniques That Make This Possible Are pipelining And parallel Processing. These Techniques Are Fundamental To Computer Architecture And Play A Vital Role In Increasing The Throughput Of Processors. For Competitive Examinations Like GATE, UGC NET, Or Other Computer Science Assessments, Understanding These Concepts In Depth Is Essential.
Introduction To Pipelining
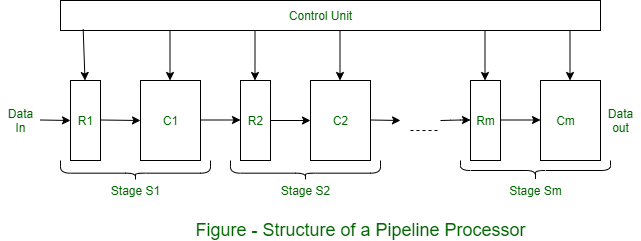
Pipelining is A Technique Used In Computer Architecture To Execute Multiple Instructions Simultaneously By Dividing The Execution Process Into Several Stages. Instead Of Processing One Instruction At A Time, Pipelining Allows Different Parts Of Multiple Instructions To Overlap In Execution. It Is Similar To An Assembly Line In A Factory Where Each Stage Performs A Specific Task And Passes The Result To The Next Stage.
A Pipelined Processor Divides Instruction Execution Into Stages Such As fetch, Decode, Execute, Memory Access, And Write-back. While One Instruction Is Being Executed, The Next Instruction Can Be Decoded, And The Following Instruction Can Be Fetched. This Overlapping Of Operations Significantly Improves System Throughput Without Increasing The Clock Speed Of The Processor.
For Example, If Each Instruction Takes Five Stages And Each Stage Takes One Clock Cycle, Executing Five Instructions In A Non-pipelined Processor Would Take 25 Cycles. In Contrast, A Pipelined Processor Can Complete All Five Instructions In Just Nine Cycles (five For The First Instruction And One Additional Cycle For Each Of The Remaining Instructions). Thus, Pipelining Enhances instruction-level Parallelism (ILP) and Boosts The Efficiency Of CPU Operations.
Stages Of Pipelining
A Typical five-stage Instruction Pipeline includes:
- Instruction Fetch (IF): The Instruction Is Fetched From Memory.
- Instruction Decode (ID): The Fetched Instruction Is Decoded To Identify The Operation And Operands.
- Execute (EX): The Instruction Operation Is Performed Using The Arithmetic Logic Unit (ALU).
- Memory Access (MEM): Data Is Read From Or Written To Memory If Required.
- Write Back (WB): The Result Of The Operation Is Written Back To The Register File.
Each Stage Works Independently, And At Any Given Time, Different Instructions Can Be In Different Stages. This Division Of Work Enables Higher Throughput And Efficiency In CPU Operations.
Types Of Pipelining
1. Arithmetic Pipelining: Used For Arithmetic Operations Like Addition, Multiplication, And Division. It Helps Speed Up The Execution Of Mathematical Computations In Floating-point Operations.
2. Instruction Pipelining: Used In Processors To Execute Multiple Instructions Simultaneously. It Improves CPU Performance By Overlapping The Execution Stages Of Multiple Instructions.
3. Processor Pipelining: This Involves Overlapping The Execution Of Multiple Processor Functions, Typically In High-performance Microprocessors.
Pipeline Hazards
Despite Its Efficiency, Pipelining Introduces Several Challenges Known As pipeline Hazards. These Are Conditions That Prevent The Next Instruction In The Pipeline From Executing In The Designated Clock Cycle.
1. Structural Hazards: Occur When Hardware Resources Are Insufficient To Support All Concurrent Operations.
2. Data Hazards: Happen When Instructions Depend On The Results Of Previous Instructions That Are Still In The Pipeline.
3. Control Hazards: Arise From Branch Instructions Or Jumps, Where The Flow Of Control Changes Unpredictably.
To Minimize These Hazards, Processors Employ Techniques Such As instruction Reordering, Branch Prediction, Forwarding, And Hazard Detection Units.
Advantages Of Pipelining
- Increased Throughput: Multiple Instructions Are Executed Simultaneously, Increasing The Number Of Instructions Processed Per Unit Time.
- Improved CPU Efficiency: Hardware Units Remain Active In All Stages Of The Pipeline.
- Reduced Instruction Latency: The Average Time Per Instruction Decreases, Improving Performance.
- Scalability: Pipelining Can Be Extended To Multiple Stages For Greater Parallelism.
Disadvantages Of Pipelining
- Complex Design: Designing A Pipelined Processor Requires Additional Control Logic And Hazard-handling Mechanisms.
- Pipeline Stalls: Hazards Can Lead To Pipeline Stalls, Reducing Performance.
- Unequal Stage Delays: If One Stage Takes More Time, It Slows Down The Entire Pipeline.
- Branch Penalty: Incorrect Branch Predictions Can Cause Instruction Flushes And Waste Cycles.
Parallel Processing – Concept And Architecture
While Pipelining Focuses On Executing Different Stages Of Multiple Instructions Simultaneously, parallel Processing involves Executing Multiple Instructions Or Tasks At The Same Time Using Multiple Processors Or Cores. It Is A More Extensive Technique That Aims To Enhance Computing Speed And Handle Large-scale Data Efficiently.
In A parallel Processing System, Two Or More Processing Units (CPUs Or Cores) Work Together To Solve A Problem Faster Than A Single Processor. Each Processor Executes A Part Of The Task Independently, And Results Are Combined To Produce The Final Output.
Parallel Processing Can Be Implemented In Both hardware And Software, Depending On System Architecture And Application Needs.
Types Of Parallel Processing
1. Bit-Level Parallelism: Improves Performance By Increasing The Word Size Of The Processor.
2. Instruction-Level Parallelism (ILP): Executes Multiple Instructions Concurrently Within A Single Processor.
3. Data-Level Parallelism (DLP): Performs The Same Operation On Multiple Data Elements Simultaneously (common In Vector Processors And GPUs).
4. Task-Level Parallelism (TLP): Executes Multiple Independent Tasks In Parallel, Often In Multiprocessor Systems.
Flynn’s Taxonomy Of Parallel Processing
Michael Flynn Classified Computer Architectures Based On Instruction And Data Streams Into Four Categories, Known As Flynn’s Taxonomy:
1. SISD (Single Instruction, Single Data): A Single Processor Executes One Instruction On One Data Stream At A Time.
2. SIMD (Single Instruction, Multiple Data): A Single Instruction Operates On Multiple Data Elements Simultaneously. Used In GPUs And Vector Processors.
3. MISD (Multiple Instruction, Single Data): Rarely Used; Multiple Instructions Operate On The Same Data.
4. MIMD (Multiple Instruction, Multiple Data): Multiple Processors Execute Different Instructions On Different Data Streams; Typical In Modern Multicore Processors.
Parallel Processing Architectures
Parallel Systems Can Be Classified Into Several Architectures:
- Shared Memory Systems: All Processors Share A Common Memory Space. Synchronization Is Achieved Using Semaphores Or Locks.
- Distributed Memory Systems: Each Processor Has Its Own Local Memory And Communicates With Others Via Message Passing.
- Hybrid Systems: Combine Both Shared And Distributed Memory Approaches For Scalability And Flexibility.
Advantages Of Parallel Processing
- Faster Execution: Multiple Processors Working Together Reduce Computation Time Significantly.
- High Throughput: Increases The Number Of Tasks Processed Simultaneously.
- Fault Tolerance: Failure Of One Processor Does Not Necessarily Halt The Entire System.
- Scalability: Easy To Add More Processors To Enhance Performance.
Challenges In Parallel Processing
- Synchronization Issues: Processors Must Coordinate To Prevent Conflicts And Data Inconsistencies.
- Load Balancing: Distributing Work Evenly Among Processors Is Crucial For Maximum Efficiency.
- Communication Overhead: Data Transfer Between Processors Can Slow Down The Overall System.
- Complex Programming: Writing Parallel Algorithms Requires Expertise In Concurrency And Synchronization.
Pipelining Vs Parallel Processing
| Aspect | Pipelining | Parallel Processing |
| Execution Type | Overlapping Stages Of Multiple Instructions | Executing Multiple Instructions Simultaneously |
| Hardware Requirement | Single CPU Divided Into Stages | Multiple CPUs Or Cores |
| Goal | Increase Instruction Throughput | Increase Overall System Performance |
| Dependency | Instructions Depend On Previous Results | Tasks May Be Independent Or Interdependent |
| Example | Instruction Pipeline In Microprocessors | Multicore CPU, GPU, And Cluster Computing |
Applications Of Pipelining And Parallel Processing
- Pipelining: Used In RISC Processors, Instruction Scheduling, And Arithmetic Operations In CPUs.
- Parallel Processing: Found In Supercomputers, High-performance Computing (HPC), AI Model Training, Weather Forecasting, Scientific Simulations, And Data Analytics.
Conclusion
Both pipelining And parallel Processing are Essential Techniques That Drive The Efficiency Of Modern Computer Systems. Pipelining Improves Instruction-level Performance By Overlapping Execution Stages, While Parallel Processing Boosts Computational Power By Utilizing Multiple Processors Simultaneously.
Together, They Form The Backbone Of Today’s High-speed Computing Environment, Enabling Faster Data Processing, Real-time Analytics, And The Power Needed For AI, Big Data, And Scientific Research. For Competitive Examinations, Understanding These Concepts Provides A Strong Foundation In Computer Architecture And Helps Students Grasp How Modern Processors Achieve Incredible Performance Levels.
Tags:
Pipelining, Parallel Processing, Pipelining In Computer Architecture, Parallel Processing Examples, Pipeline Hazards
